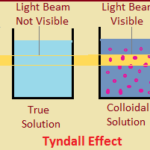
Question 1 What are colloids. Give example? Question 2 What do you mean by Tyndall effect? Question 3 Give properties of colloids? Question 4 What are sol.Give example? Question 5 What are aerosol.Give example? Question 6 What are emulsions.Give example? Question 7 What are foam.Give example? Question 8 What is the difference between solution and … [Read more...] about Colloids